
Estudo de Caso: Transformando PDF's em API
No nosso estudo de hoje iremos abordar como utilizamos Playwright, Azure Logic Apps, Azure Container Instance e Azure Form Recognizer para extrair dados de múltiplos PDFs e criar uma API.

Iniciando uma nova categoria de posts por aqui, quero compartilhar de tempos em tempos alguns estudos de caso envolvendo ferramentas do Azure.
No nosso estudo de hoje iremos abordar como utilizamos Playwright, Azure Logic Apps, Azure Container Instance e Azure Form Recognizer para extrair dados de múltiplos PDFs e criar uma API.
Desafio
Similar ao Brasil, nos Estados Unidos existem vários concelhos profissionais para várias áreas da saúde, cada estado tem seu próprio conselho.
Esses conselhos publicam documentos regulares de profissionais que tiveram sua licença suspensa por um período ou permanentemente, cada conselho publica essas informações de um modo, sendo a maioria em PDFs e Excel.
Como a empresa vende serviços de validação de diplomas e registros nos concelhos estávamos procurando uma maneira de automatizar essas consultas e criar uma API que o sistema principal pudesse checar se um determinado profissional está banido ou não de exercer a profissão.
Os principais desafios são:
- Recuperar os arquivos: Os sites não possuem APIs e nem um período pré-determinado para publicação.
- Extrair os dados dos arquivos: Os arquivos no formato Excel são mais fáceis de extrair os dados, mas transformar os dados do PDF de uma forma confiável já fica um pouco mais difícil.
Solução proposta
Para recuperar os arquivos decidimos utilizar o Playwright que é uma ferramenta de automação em cima do Chromium.
Após testar algumas ferramentas pagas, optamos pelo Azure Form Recognizer para fazer a extração dos dados.
Como precisamos rodar a ferramenta todos os dias para checar por novos arquivos adicionamos o Azure Logic Apps para termos um agendamento para rodar nosso contêiner no Azure Container Instance que é cobrado apenas por tempo de execução.
A execução ficou assim:
- Azure Logic Apps: Inicia uma nova execução do Azure Container Instance todos os dias as 8:00AM.
- Azure Container Instance: Executa um contêiner com imagem customizada, que possui uma console app com toda a lógica a aplicação.
- Aplicação: Para cada site suportado, inicia uma instância do Playwright, verifica se existe um novo arquivo, em caso positivo faz o download e envia para o Azure Form Recognizer.
- Azure Form Recognizer: Transforma o texto do PDF em um JSON estruturado, para nós o interessante é a função que retorna tabelas de forma estruturada.
Uma vez com os dados em formato JSON aplicamos algumas regras do negócio e inserimos no banco de dados que a API utiliza posteriormente para rodar as consultas.
Para não ficar só nas minhas palavras, segue um código de exemplo fazendo o parse de um arquivo PDF e utilizando o Azure Form Recognizer para fazer o parse da tabela.
O único pacote que precisa ser referenciado é o Azure.AI.FormRecognizer.
class Program
{
private static readonly string endpoint = "https://seu-form-recognizer.cognitiveservices.azure.com/";
private static readonly string apiKey = "sua-api-key";
private static readonly AzureKeyCredential Credential = new AzureKeyCredential(apiKey);
static async Task Main(string[] args)
{
var fileName = "seu-arquivo.pdf";
var sampleDocument = File.OpenRead(fileName);
var watch = Stopwatch.StartNew();
var client = new FormRecognizerClient(new Uri(endpoint), Credential);
var formPages = await client.StartRecognizeContentAsync(sampleDocument)
.WaitForCompletionAsync();
watch.Stop();
Console.WriteLine($"Time to convert file: {watch.Elapsed:g}");
foreach (var page in formPages.Value)
{
if (!page.Tables.Any())
{
continue;
}
var fileData = new List<string>();
var table = page.Tables.First();
var rows = table.Cells.GroupBy(c => c.RowIndex).ToList();
foreach (var row in rows)
{
var cells = row.ToList();
var line = cells[0].Text;
line += $" | {cells[1].Text}";
line += $" | {cells[2].Text}";
line += $" | {cells[3].Text}";
line += $" | {cells[4].Text}";
fileData.Add(line);
}
await File.WriteAllLinesAsync($"{fileName}_{page.PageNumber}.txt", fileData);
}
Console.WriteLine("Done!");
}
}
Custos
Se você chegou até aqui deve estar curioso quanto uma solução dessa custa por mês. O custo estimado total é de $10.49 USD.
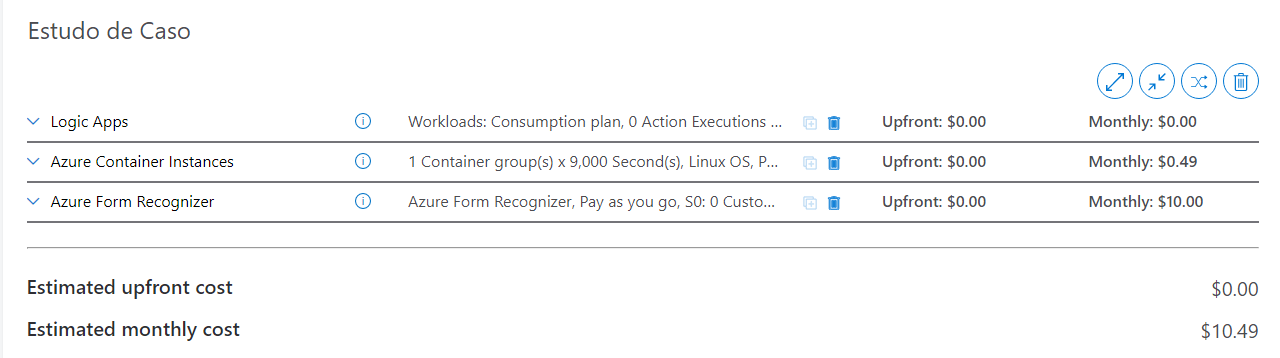
- Azure Logic Apps: Temos direito a 4 mil execuções por mês gratuitas. Como fazemos uma unica execução por dia iremos utilizar apenas 30, então no nosso caso o serviço não terá custos.
- Azure Container Instances: O código leva em média 5 minutos para executar todos os crawlers e parses, como pagamos apenas pelo hardware utilizado (no caso 2 vcpus e 4 gb de memória) em 30 dias gastaremos apenas $0.49
- Azure Form Recognizer: Temos direito a 500 páginas gratuitas por mês, na solução proposta guardamos o hash do arquivo e apenas processamos em caso de mudança, mas mesmo estimando uma média de 1000 páginas por mês nosso custo é de apenas $10.00.
Links Uteis
- Exemplos do Azure Form Recognizer: https://learn.microsoft.com/en-us/samples/azure/azure-sdk-for-net/azure-form-recognizer-client-sdk-samples/?view=form-recog-3.0.0
- Primeiros passos com o Playwright: https://playwright.dev/dotnet/docs/library
- Exemplos do Logic Apps: https://learn.microsoft.com/en-us/samples/browse/?products=azure-logic-apps
- Exemplos do Azure Container Instance: https://learn.microsoft.com/en-us/samples/browse/?products=azure&terms=container%2Binstance
Conclusão
De uma maneira simples e objetiva conseguimos propor uma solução altamente escalável e de baixo custo que resolveu o problema do cliente. Foi um desafio bem legal de se implementar e ver funcionando em produção.
E você, como resolveria de alguma outra forma? Gostaria de saber mais detalhes de alguma das implementações?





