

O objetivo desse post é abordar o uso do Cluster Autoscaler e sua relação com o Horizontal POD Autoscaler (HPA), Kube-scheduler e cloud-controller-manager.
Ao criar um cluster Kubernetes em uma plataforma de nuvem, a configuração inicial muitas vezes não inclui várias ferramentas importantes, como o Cluster Autoscaler e o metric-server. E não fazer isso há impactos diretos nos custos. Porém não basta só adicionar, é necessário também configurar o HPA. Entender como o HPA e o Cluster Autoscaler trabalham juntos é crucial, pois é a partir dos outputs gerados pelo HPA que o Cluster Autoscaler faz o trabalho dele.
Horizontal POD Autoscaler
O HPA ajusta automaticamente o número de réplicas de um POD que está sendo controlado por algum controller (geralmente o Deployment). O HPA vai analisar as métricas dos PODs em intervalos regulares, calculando o número de réplicas necessário de acordo com a métrica configurada (CPU, memória etc). Se ele identificar que é necessário ajustar o número de réplicas, vai ajustar o campo Replicas no recurso, seja ele um Deployment, ReplicaSet ou ReplicationController.
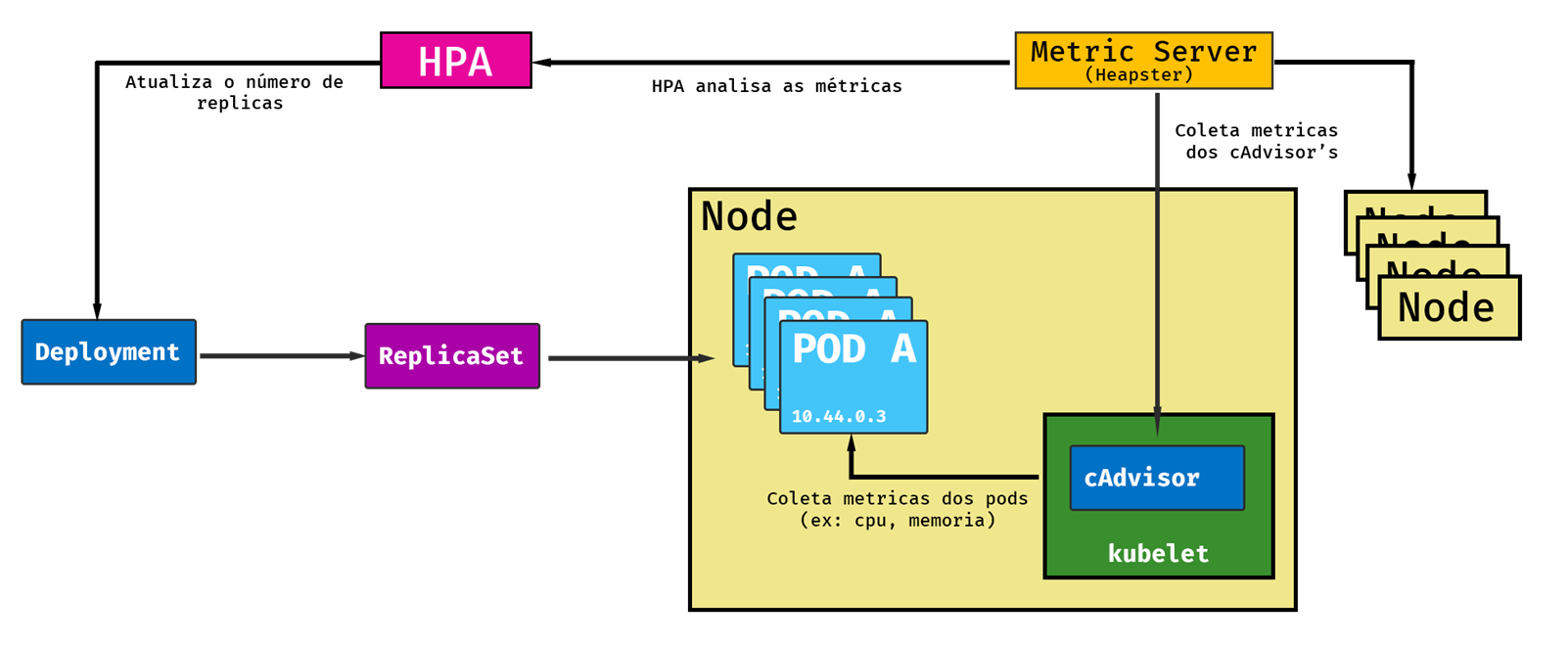
Entendendo o processo por debaixo do capô
O processo do HPA PODe ser dividido em três etapas:
- Obter as métricas de todos os PODs.
- Calcular o número de PODs necessário.
- Atualizar o campo de réplicas do controller.
O HPA não realiza por si só a coleta de métricas dos PODs. Ele obtém de uma outra fonte.
As métricas dos PODs e do node são coletadas por um componente chamado cAdvisor (Container advisor), é um agente do Kubelet. Lembrando que todo Worker Node do cluster possui um Kubelet rodando. Esses dados do cAdvisor são coletados por um outro componente, o metric-server (Antigo Heapster).
O HPA, por sua vez, faz uma consulta ao metric-server, por meio de chamadas REST, e obtem as métricas dos PODs do qual ele está monitorando. Uma vez em posse dessas métricas ele faz alguns cálculos para para determinar o número necessário de réplicas. Nesse momento entra em ação o Kube-scheduler, um outro componente do Kubernetes, que vai buscar um Node para agendar esse novo POD.
Cluster Autoscaler
O Cluster Autoscaler é uma ferramenta fundamental para o dimensionamento automático dos NODES em um cluster Kubernetes. Enquanto o Horizontal POD Autoscaler (HPA) foca no escalonamento dos PODS, o Cluster Autoscaler tem a responsabilidade de ajustar a quantidade de NODES. E é necessário entender a interdependência entre o HPA e o Cluster Autoscaler, pois o correto funcionamento de um, depende do outro.
Quando o HPA aumenta o número de PODs para atender à demanda, PODe ocorrer uma situação em que o kube-scheduler não encontra um Node com recursos suficientes, como CPU e memória, para hospedar a nova réplica. Nesse cenário, surge a seguinte mensagem de erro:
0/3 nodes are available: 3 Insufficient cpu, 3 Insufficient memory.
É neste ponto que o Cluster Autoscaler entra em ação. Ele detecta a falta de recursos e, baseado em suas configurações, inicia o processo para adicionar um novo Node ao cluster. Então, por debaixo do capô o cloud-controller-manager vai se comunicar com o provedor de nuvem (Azure ou AWS), iniciando o processo de provisionamento de um novo Node.
Dessa forma, o Cluster Autoscaler garante que o cluster sempre tenha recursos suficientes para atender às necessidades dos PODs, otimizando tanto o desempenho quanto a eficiência de custos. Além disso, ele também PODe remover Nodes desnecessários durante períodos de baixa demanda, contribuindo para uma gestão de recursos mais eficiente e econômica.
Definição de Resources e o uso do HPA
No Kubernetes, o comportamento de uma aplicação é definido por meio de manifestos. Para que o autoscaling, tanto de Nodes quanto de PODs, funcione adequadamente, é essencial configurar o Deployment ou ReplicaSet com valores apropriados de CPU e Memória na seção Resources, setando valores de Requests e Limits.
Requests e Limits são especificações que determinam a quantidade de recursos que um POD precisa. Enquanto Requests especifica o mínimo de recursos garantidos pelo Kubernetes para o POD, Limits estabelece o teto de recursos que o POD PODe utilizar. Essas definições não só otimizam o uso de recursos, mas também são fundamentais para o funcionamento eficiente do HPA, que baseia suas decisões de scaling nessas informações. Consequentemente, o Cluster Autoscaler também depende desses dados para sua operação.
É muito importante configurar corretamente os valores de CPU e memória. Nesse exemplo se sua aplicação utilizar mais que 150Mi de memória por padrão, o primeiro impacto é que eventualmente PODe ocorrer throttling. Segundo que isso vai impactar no uso do HPA, bem como haverá impacto no Cluster Autoscaler.
Conclusão
Ao criar um cluster, não basta adicionar o Cluster Autoscaler, configurar o HPA e incluir um metric-server. Estes itens são cruciais, mas tudo começa com a definição correta de CPU e Memória para cada aplicação.
É um tanto comum ver a configuração inadequada desses valores, algumas vezes até estabelecidas por padrão em um Chart Helm, e isso com certeza vai ser um obstáculo para o autoscaling eficiente do cluster. Tanto para adicionar recursos que não serão utilizados como também causar problemas de Throttling.




